Statistics Analysis
The SQL Server optimizer is cost based and its the statistics available to the optimizer that it considers when searching for an optimal query plan. The optimizer must have information about the data that defines an index or a column. That information is referred to as a statistic. Statistics define both the distribution of data and the uniqueness or selectivity of the data. Statistics are maintained both on indexes and on columns within the system
The Role of Statistics in Query Optimization
SQL Server’s query optimizer is a cost-based optimizer; it decides on the best data access mechanism and join strategy by identifying the selectivity, how unique the data is, and which columns are used in filtering the data (meaning via the WHERE or JOIN clause). Statistics exist with an index, but they also exist on columns without an index that are used as part of a predicate. As long as you ensure that the default statistical settings for the database are set, the optimizer will be able to do its best to determine effective processing strategies dynamically.
Statistics on an Indexed Column
The usefulness of an index is largely dependent on the statistics of the indexed columns; without statistics, SQL Server’s cost-based query optimizer can’t decide upon the most effective way of using an index. To meet this requirement, SQL Server automatically creates the statistics of an index key whenever the index is created. It isn’t possible to turn this feature off.
Statistics on a Nonindexed Column
Sometimes you may have columns in join or filter criteria without any index. Even for such nonindexed columns, the query optimizer is more likely to make the best choice if it knows the cardinality and data distribution, also known as the statistics, of those columns.
In addition to statistics on indexes, SQL Server can build statistics on columns with no indexes. The information on data distribution, or the likelihood of a particular value occurring in a nonindexed column, can help the query optimizer determine an optimal processing strategy.
Analyzing Statistics
We use the DBCC command to show the statistics of columns and indexes as follows :
DBCC SHOW_STATISTICS('Person.Person', 'IX_Person_LastName_FirstName_MiddleName')
to show the statistics on the index IX_Person_LastName_FirstName_MiddleName on the Person.Person table.
These steps consist of varying size intervals between the 200 values stored. A step provides the following information:
- The top value of a given step (RANGE_HI_KEY)
- The number of rows equal to RANGE_HI_KEY (EQ_ROWS)
- The number of rows between the previous top value and the current top value, without counting either of these boundary points (RANGE_ROWS)
- The number of distinct values in the range (DISTINCT_RANGE_ROWS); if all values in the range are unique, then RANGE_ROWS equals DISTINCT_RANGE_ROWS
- The average number of rows equal to any potential key value within a range (AVG_RANGE_ROWS)
For example, when referencing an index, the value of AVG_RANGE_ROWS for a key value within a step in the histogram helps the optimizer decide how (and whether) to use the index when the indexed column is referred to in a WHERE clause. Because the optimizer can perform a SEEK or SCAN operation to retrieve rows from a table, the optimizer can decide which operation to perform based on the number of potential matching rows for the index key value. This can be even more precise when referencing the RANGE_HI_KEY since the optimizer can know that it should find a fairly precise number of rows from that value (assuming the statistics are up-to-date).
Showing statistics on an a table as follows :
SELECT s.name,
s.auto_created,
s.user_created,
s.filter_definition,
sc.column_id,
c.name AS ColumnName
FROM sys.stats AS s
JOIN sys.stats_columns AS sc ON sc.stats_id = s.stats_id
AND sc.object_id = s.object_id
JOIN sys.columns AS c ON c.column_id = sc.column_id
AND c.object_id = s.object_id
WHERE s.object_id = OBJECT_ID('Production.Product');
Inspecting Statistics Objects
Existing statistics for a specific object can be displayed using the sys.stats catalog view, as used in the following query:
-- existing statistics for a specific object can be displayed using the sys.stats catalog view, as used in the following query:
SELECT * FROM sys.stats
WHERE object_id = OBJECT_ID('Sales.SalesOrderDetail')
For example, run the following statement to verify that there are no statistics on the UnitPrice column of the Sales.SalesOrderDetail table:
DBCC SHOW_STATISTICS (‘Sales.SalesOrderDetail’, UnitPrice)
By then running the following query, the query optimizer will automatically create statistics on the UnitPrice column, which is used in the query predicate:
-- by then running the following query, the query optimizer will automatically create statistics on the UnitPrice column
SELECT * FROM Sales.SalesOrderDetail
WHERE UnitPrice = 35
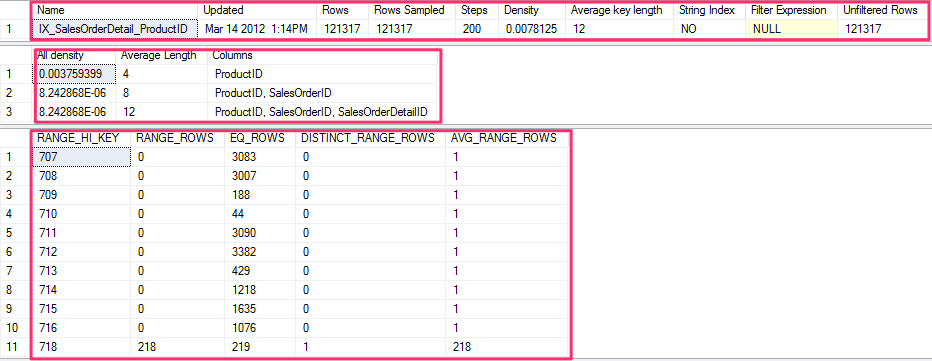
Running the previous DBCC SHOW_STATISTICS statement again will now show a statistics object. The output is separated into three result sets called the header, the density vector, and the histogram.
Density
To better explain the density vector, run the following statement to inspect the statistics of the existing index, IX_SalesOrderDetail_ProductID:
DBCC SHOW_STATISTICS (’Sales.SalesOrderDetail’, IX_SalesOrderDetail_ProductID)
Density, which is defined as 1 / “number of distinct values,” is listed in the All density field, and it is calculated for each set of columns, forming a prefix for the columns in the statistics object.

Density information can be used to improve the query optimizer’s estimates for GROUP BY operations, and on equality predicates where a value is unknown, as in the case of a query using local variables.
-- in this case, we have 1 / 0.003759399, which gives us 266, which is the estimated number of rows shown in the plan
SELECT ProductID FROM Sales.SalesOrderDetail
GROUP BY ProductID
Next is an example of how the density can be used to estimate the cardinality of a query using local variables:
-- next is an example of how the density can be used to estimate the cardinality of a query using local variables:
DECLARE @ProductID int
SET @ProductID = 921
SELECT ProductID FROM Sales.SalesOrderDetail
WHERE ProductID = @ProductID
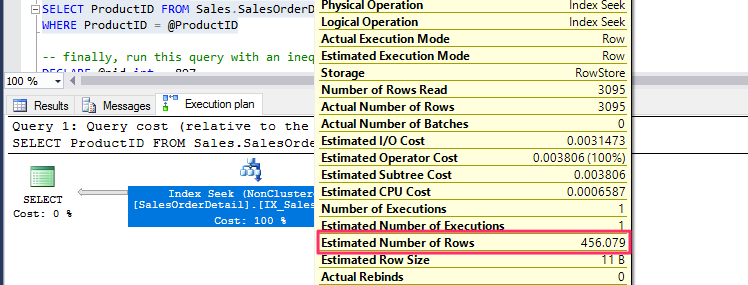
In this case, the query optimizer does not know the value of the @ProductID local variable at optimization time, so it is not able to use the histogram. The estimated number of rows is obtained using the density multiplied by the number of records in the table, which in our example is 0.003759399 * 121317, or 456.079.
Actually, because the query optimizer does not know the value of @ProductID at optimization time, the value 921 in the previous listing does not matter; any other value will give exactly the same estimated number of rows and execution plan, this being the average number of rows per value. Finally, run this query with an inequality operator:
-- finally, run this query with an inequality operator:
DECLARE @pid int = 897
SELECT * FROM Sales.SalesOrderDetail
WHERE ProductID < @pid
Just as before, the value 897 does not matter; any other value will give you the same estimated number of rows and execution plan. However, this time, the query optimizer is not able to use the density information and instead is using the standard guess of 30 percent selectivity for inequality comparisons. This means that the estimated number of rows is always 30 percent of the total number of records for an inequality operator; in this case, 30 percent of 121,317 is 36,395.1
Cardinality Estimation Errors
Cardinality estimation errors can lead to the query optimizer making poor choices as to how best to execute a query and, therefore, to badly performing execution plans. In the next query, I show you how to use the SET STATISTICS PROFILE statement with one of our previous examples, where SQL Server is making a blind guess regarding the selectivity of certain columns:
-- in the next query, I show you how to use the SET STATISTICS PROFILE statement
SET STATISTICS PROFILE ON
GO
SELECT * FROM Sales.SalesOrderDetail
WHERE OrderQty * UnitPrice > 10000
GO
SET STATISTICS PROFILE OFF
GO
Using this output, you can easily compare the actual number of rows, shown on the Rows column, against the estimated number of records, shown on the EstimateRows column, for each operator in the plan.
Introduced with SQL Server 2012, the inaccurate_cardinality_estimate extended event can also be used to detect inaccurate cardinality estimations by identifying which query operators output significantly more rows than those estimated by the query optimizer.
Recommendations
- auto-create and auto-update statistics default configurations
- updating statistics using WITH FULLSCAN
- avoiding local variables in queries
- avoiding non-constant-foldable or complex expressions on predicates using computed columns, and considering multicolumn or filtered statistics
Statistics on Computed Columns
SQL Server can automatically create and update statistics on computed columns.
-- to see an example, run this query
SELECT * FROM Sales.SalesOrderDetail
WHERE OrderQty * UnitPrice > 10000
The estimated number of rows is 36,395.1, which is 30 percent of the total number of rows (121,317), although the query returns only 772 records. SQL Server is obviously using a selectivity guess because it cannot estimate the selectivity of the expression OrderQty * UnitPrice > 10000.
Now create a computed column:
-- now create a computed column:
ALTER TABLE Sales.SalesOrderDetail
ADD cc AS OrderQty * UnitPrice
Run the previous SELECT statement again, and note that, this time, the estimated number of rows has changed and is close to the actual number of rows returned by the query.
Note that creating the computed column does not create statistics; these statistics are created the first time the query is optimized, and you can run the next query to display the information about the statistics objects for the Sales.SalesOrderDetail table:
-- note that creating the computed column does not create statistics
SELECT * FROM sys.stats
WHERE object_id = OBJECT_ID('Sales.SalesOrderDetail')
The newly created statistics object will most likely be at the end of the list. Copy the name of the object, and use the following command to display the details about the statistics object
-- use the following command to display the details about the statistics object
DBCC SHOW_STATISTICS ('Sales.SalesOrderDetail', _WA_Sys_0000000E_44CA3770)
Unfortunately, for automatic matching to work, the expression must be exactly the same as the computed column definition. So, if I change the query to UnitPrice * OrderQty, instead of OrderQty * UnitPrice, the execution plan will show an estimated number of rows of 30 percent again, as this query will demonstrate:
-- unfortunately, for automatic matching to work, the expression must be exactly the same as the computed column definition
SELECT * FROM Sales.SalesOrderDetail
WHERE UnitPrice * OrderQty > 10000
Finally, drop the created computed column:
-- finally, drop the created computed column:
ALTER TABLE Sales.SalesOrderDetail
DROP COLUMN cc
Statistics Maintenance
SQL Server allows a user to manually override the maintenance of statistics in an individual database. The four main configurations controlling the automatic statistics maintenance behavior of SQL Server are as follows:
- New statistics on columns with no index (auto create statistics)
- Updating existing statistics (auto update statistics)
- The degree of sampling used to generate statistics
- Asynchronous updating of existing statistics (auto update statistics async)
If you want to check the status of whether a table has its automatic statistics turned off, you can use this:
EXEC sp_autostats 'HumanResources.Department';
Reset the automatic maintenance of the index so that it is on where it has been turned off.
EXEC sp_autostats
'HumanResources.Department',
'ON';
EXEC sp_autostats
'HumanResources.Department',
'ON',
AK_Department_Name;
Analyzing the Effectiveness of Statistics
You can verify the current settings for the autostats feature using the following:
- sys.databases
- DATABASEPROPERTYEX
- sp_autostats
- Status of Auto Create Statistics
You can verify the current setting for auto create statistics by running a query against the sys.databases system table.
SELECT is_auto_create_stats_on
FROM sys.databases
WHERE [name] = 'AdventureWorks2012';
A return value of 1 means enabled, and a value of 0 means disabled.
You can also verify the status of specific indexes using the sp_autostats system stored procedure, as shown in the following code.
USE AdventureWorks2012;
EXEC sys.sp_autostats
'HumanResources.Department';