Performance Tuning Overview
Factors Impacting Performance
There are several factors that impact the application performance, although in this guide we will be more concerned with the factors that are related to SQL Server specifically. Here are some factors that impact performance and scalability :
- Application Architecture
- Application Design
- Transactions and Isolation Levels
- Transact-SQL Code
- Hardware Resources
- SQL Server Configuration
SQL Server Configuration
To view the sql server configuration options you can use the stored procedure, sp_configure. You can show configurations options as follows :
exec sp_configure
The above will not show advanced configuration options, you can toggle the display of advanced configurations by running the following :
EXEC sp_configure 'show advanced options', 1
GO
RECONFIGURE
The Performance-Tuning Process
Performance tuning needs to be a proactive process not reactive. A general good strategy might entail the following :
- Creating a baseline for your workload
- Monitoring your workload
- Detecting, isolating, and troubleshooting performance problems
You should ask yourself the following general questions before embarking on the performance tuning process :
- Is any other resource-intensive application running on the same server?
- Is the capacity of the hardware subsystem capable of withstanding the maximum workload?
- Is SQL Server configured properly?
- Does the shared environment, whether VM or platform, have adequate resources, or am I dealing with a configuration issue there or even resource contention from outside forces?
- Is the database connection between SQL Server and the database application efficient?
- Does the database design support the fastest data retrieval (and modification for an updatable database)?
- Is the user workload, consisting of SQL queries, optimized to reduce the load on SQL Server?
- What processes are causing the system to slow down as reflected in the measurement of various wait states, performance counters, and dynamic management objects?
- Does the workload support the required level of concurrency?
Creating a Baseline
A baseline is what you will use to check deviations in performance within your sql server environment. Some environments might even require multiple baselines depending on the application requirements e.g a baseline for OLTP(Online Transaction Processing) workloads and another baseline for OLAP(Online Analytical Processing) workloads.
Here are some commonly used tools for creating a SQL Server Performance Baseline :
- Performance Monitor
- SQL Server Profiler(Deprecated since 2012, Use Extended Events instead)
- Extended Events
- Database Engine Tuning Advisor (DTA)
- DBCC Commands
- Dynamic Management Views (DMV) and Functions (DMF)
Monitoring the Workload
The baseline is not useful if its not monitored. A plan should be put in place to monitor the baseline. Any significant deviation from baseline represents a change that needs to be understood and analyzed for its impact on the performance of your workload
Detecting, Isolating, and Troubleshooting Common Performance Problems
Performance problems usually manifest themselves as a bottleneck in a subsystem within SQL Server and these can be :
- CPU
- Memory
- I/O
- tempdb
- Blocking
CPU Bottlenecks
When a user submits a query that query is either a batch or a request. Each request or batch is executed by a worker process, which is a logical thread in SQL Server, and is mapped directly to an OS thread or a fiber. A worker process can be either in three states :
- RUNNING - The worker is currently executing on the CPU
- RUNNABLE - The worker is currently waiting for its turn on the CPU
- SUSPENDED - The worker is waiting on a resource, for example, a lock or an I/O
If the SQL Server instance have a large number of workers in the RUNNABLE state this could be a sign of a CPU bottleneck and if more workers are spending their time in the SUSPENDED state they could be a blocking issue, which might be related to I/O or another resource.
Detecting CPU Bottlenecks
The following tools can help detect CPU bottleneck :
- Performance Monitor
- DMVs
Performance Monitor Counters
We can use the the following Performance counters to detect CPU pressure :
- Processor:% Processor Time - A consistent value greater than 80 percent for 15 to 20 minutes indicates that you have CPU bottleneck.
- System:Processor Queue - A sustained value of 2 or higher typically indicates CPU pressure
- Process:%Processor Time - If SQL Server is the only application on the machine then you can monitor this value and check the amount of CPU time used by SQL Server.
Using DMVs
We can check the number of worker processes for each scheduler that are in the RUNNABLE state using the sys.dm_os_schedulers and `` as follows :
select s.scheduler_id, count(*) [workers waiting for cpu] from sys.dm_os_workers w
join sys.dm_os_schedulers s
on w.scheduler_address = s.scheduler_address
where s.scheduler_id < 255 and w.state = N'RUNNABLE'
group by s.scheduler_id
or we can find out the amount of time spent by workers in the RUNNABLE state as follows :
SELECT SUM(signal_wait_time_ms)
FROM sys.dm_os_wait_stats
signal_wait_time represents the difference in time when the worker process actually started running from the RUNNABLE state.
Note
The above DMVs contains values since SQL Server was started. You will need to use a baseline to find significant deviations in order to detect CPU pressure.
Isolating and troubleshooting of CPU bottlenecks
Once you are convinced the pressure is cause by CPU bottleneck, you can diagnose the causes. The following are some causes of CPU pressure :
- An inefficient query plan
- Excessive compilation and recompilation
An inefficient query plan
We need to find the queries taking the most CPU time first and comapre them to the baseline. We can use the sys.dm_exec_query_stats. This DMV returns aggregate performance statistics on cached query plans in SQL Server. We can find the top queries with high CPU per execution with the following :
USE AdventureWorks2012;
GO
SELECT TOP 10 query_stats.query_hash AS "Query Hash",
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS "Avg CPU Time",
MIN(query_stats.statement_text) AS "Statement Text"
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) as ST) as query_stats
GROUP BY query_stats.query_hash
ORDER BY 2 DESC;
or a variation of the above :
SELECT TOP 10
total_worker_time/execution_count AS avg_cpu_cost, plan_handle,
execution_count,
(SELECT SUBSTRING(text, statement_start_offset/2 + 1,
(CASE WHEN statement_end_offset = -1
THEN LEN(CONVERT(nvarchar(max), text)) * 2
ELSE statement_end_offset
END - statement_start_offset)/2)
FROM sys.dm_exec_sql_text(sql_handle)) AS query_text
FROM sys.dm_exec_query_stats
ORDER BY [avg_cpu_cost] DESC
We might miss frequently executed queries by using the above, a slight modification is to find frequently executed queries as follows :
SELECT TOP 10 total_worker_time, plan_handle,execution_count,
(SELECT SUBSTRING(text, statement_start_offset/2 + 1,
(CASE WHEN statement_end_offset = -1
THEN LEN(CONVERT(nvarchar(max),text)) * 2
ELSE statement_end_offset
END - statement_start_offset)/2)
FROM sys.dm_exec_sql_text(sql_handle)) AS query_text
FROM sys.dm_exec_query_stats
ORDER BY execution_count DESC
The following example returns row count aggregate information (total rows, minimum rows, maximum rows and last rows) for queries :
SELECT qs.execution_count,
SUBSTRING(qt.text,qs.statement_start_offset/2 +1,
(CASE WHEN qs.statement_end_offset = -1
THEN LEN(CONVERT(nvarchar(max), qt.text)) * 2
ELSE qs.statement_end_offset end -
qs.statement_start_offset
)/2
) AS query_text,
qt.dbid, dbname= DB_NAME (qt.dbid), qt.objectid,
qs.total_rows, qs.last_rows, qs.min_rows, qs.max_rows
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
WHERE qt.text like '%SELECT%'
ORDER BY qs.execution_count DESC;
Note
The above DMVs only contains aggregate performance information for queries that have the plans cached. Some expensive queries plans might not be cached and will be missed. But if you are polling for this information frequently you will be able to catch them.
Excessive compilation and recompilation
SQL Server compiles the query before executing it and usually caches the plan. For an expensive query the cost of re-compiling can be reducing by re-using cached query plans. Compiling is a CPU intensive task and excessive re-compilation will result in CPU pressure. There many reasons SQL Server might recompile a query, some of them are :
- Schema Change - f the metadata of the referenced objects is changed, it causes a recompile. So if you have a batch that mixes DDL and DML, it will force a recompile
- SET Options - There are some set options which will cause a recompile, if changed. Some of these options are ANSI_NULLS, ANSI_PADDINGS, ANSI_NULL, and ARITHABORT. If you change these options inside a batch, it will force a recompile every time
- Updated Statistics - Any significant changes in the statistical information will force a recompile
- Recompile Query Hint - If you have a stored procedure with recompile option, it will get recompiled on every execution
Detecting Compilation and Re-compilation
We can use Performance Monitor and DMVs to monitors compilations and recompilations.
Performance Counters
We can look at the following Performance Counters :
SQLServer: SQL Statistics: Batch Requests/Sec
SQLServer: SQL Statistics: SQL Compilations/Sec
SQLServer: SQL Statistics: SQL Recompilations/Sec
Note
It is important to look at compile/recompile numbers in relation to number batch requests per second
Using DMVs
We can check how much time the SQL Server optimizer is spending optimizing the query plan using the `` DMV as follows :
SELECT * FROM sys.dm_exec_query_optimizer_info
WHERE counter in ('optimizations', 'elapsed time')
We can use the following query to find the top 10 queries with the most recompiles as follows :
SELECT TOP 10 plan_generation_num, execution_count,
(SELECT SUBSTRING(text, statement_start_offset/2 + 1,
(CASE WHEN statement_end_offset = -1
THEN LEN(CONVERT(nvarchar(max),text)) * 2
ELSE statement_end_offset
END - statement_start_offset)/2)
FROM sys.dm_exec_sql_text(sql_handle)) AS query_text
FROM sys.dm_exec_query_stats
WHERE plan_generation_num >1
ORDER BY plan_generation_num DESC
Recompilations might mean SQL Server is under memory pressure and can not keep the cached plans in memory. We can look at the memory using DBCC as follows :
DBCC MEMORYSTATUS
Look under the Procedure Cache tab results. TotalPages represent stolen buffer pool pages used to store optimized plans. Here is the sample output :
Procedure Cache Value
---------------------------------------- -----------
TotalProcs 0
TotalPages 211
InUsePages 0
(3 row(s) affected)
Memory Bottlenecks
All data read from tables needs to be in memory first before SQL Server can work with it. The first time SQL Server reads a page from the file, this is called a physical read and when the page is read from memory its called a logical read. SQL Server keeps the pages in memory structure called the buffer pool. Its uses the LRU(Least Recently Used) algorithm to keep the pages in memory.
SQL Server also uses memory for its internal structures, e.g. for user connections, locks, query cache and other internal structures.
SQL Server uses both physical RAM and virtual memory. A page file is used for the virtual memory. When a process is not using a part of memory, the data is paged to disk and then paged in again when the process needs to use them. This process is quite slow. Paging can also be the result of not having enough RAM on the machine.
Show Available Memory
We can use DBCC to show the available memory and paging memory as follows :
DBCC MEMORYSTATUS
Here is a sample output :
Process/System Counts Value
---------------------------------------- --------------------
Available Physical Memory 3500609536
Available Virtual Memory 140714606923776
Available Paging File 2413473792
Working Set 168247296
Percent of Committed Memory in WS 13
Page Faults 1821744
System physical memory high 1
System physical memory low 0
Process physical memory low 0
Process virtual memory low 0
(10 row(s) affected)
Detecting Memory Pressure
Using Performance Monitor we can look at the following counters :
- Memory: Available Bytes - This represents the amount of physical memory, in bytes, available to processes running on the computer.
- SQLServer:Buffer Manager: Buffer Cache Hit Ratio - This represents the percentage of pages that were found in the buffer pool without having to incur a read from disk. For most production workloads this value should be in the high 90s
- SQLServer:Buffer Manager: Page Life Expectancy - This represents the number of seconds a page will stay in the buffer pool without references. A lower value indicates that the buffer pool is under memory pressure.
- SQLServer:Buffer Manager: Checkpoint Pages/Sec - This represents number of pages flushed by checkpoint or other operations that require all dirty pages to be flushed. This indicates increased buffer pool activity of your workload
- SQLServer:Buffer Manager: Lazywrites/Sec - This represents number of buffers written by buffer manager’s lazy writer. This indicates increased buffer pool activity of your workload.
The majority of the committed memory is used by the buffer pool on a SQL Server instance can be seen from the output of DBCC MEMORYSTATUS. Here is the sample output :
Buffer Pool Value
---------------------------------------- -----------
Database 6005
Simulated 1104
Target 16203776
Dirty 162
In IO 0
Latched 0
Page Life Expectancy 105067
(7 row(s) affected)
- Committed - This value shows the total buffers that are committed. Buffers that are committed have physical memory associated with them. The Committed value is the current size of the buffer pool.
- Target - This value shows the target size of the buffer pool. It is computed periodically by SQL Server as the number of 8-KB pages it can commit without causing paging. SQL Server lowers its value in response to memory low notification from the Windows operating system. A decrease in the number of target pages on a normally loaded server may indicate response to an external physical memory pressure.
Isolation and Troubleshooting of Memory Pressure
Use the Performance counters to detect external memory pressure. The following are some counters to look at :
Process:Working Set counter for each process
Memory:Cache Bytes counter for system working set
Memory:Pool Nonpaged Bytes counter for size of unpaged pool
Memory:Available Bytes (equivalent of the Available value in Task Manager)
We can use the following DMV to find the amount of memory currently being used by the buffer pool :
SELECT
SUM(virtual_memory_committed_kb + shared_memory_committed_kb
+ awe_allocated_kb) AS [Used by BPool, Kb]
FROM sys.dm_os_memory_clerks
WHERE type = 'MEMORYCLERK_SQLBUFFERPOOL'
I/O Bottlenecks
The IO subsystem is an important part of SQL Server. SQL Server needs to read data pages from the file before it can work with. Sometimes IO bottlenecks are the result os a different subsystem, e.g memory pressure.
Detection of I/O Bottlenecks
We can use Performance Monitor and look at counters for I/O. Here are some counters to look at :
- PhysicalDisk Object: Avg. Disk Queue Length - Disk Queue Length represents the average number of physical Read and Write requests that were queued on the selected physical disk during the sampling period. If your I/O system is overloaded, more Read/Write operations will be waiting. If your disk-queue length frequently exceeds a value of two per physical disk during peak usage of SQL Server, then you might have an I/O bottleneck
PhysicalDisk Object: Avg. Disk Sec/Read or Avg - is the average time, in seconds, of a read or write of data from/to the disk. Some general guidelines follow:
Less than 10 ms is very good
Between 10 and 20 ms is okay
Between 20 and 50 ms is slow, needs attention
Greater than 50 ms is considered a serious I/O bottleneck
PhysicalDisk: Disk Reads/Sec or Disk Writes/Sec - is the rate of read or write operations on the disk. You need to make sure that this number is less than 85 percent of the disk capacity. The disk access time increases exponentially beyond 85 percent capacity.
Note
The Performance counter shows the I/O information at the disk level not file level. If you are mixing the database files and the logs files on the same disk you miss valuable information.
We can use the DMV to find the I/O information at the file level as follows :
SELECT database_id, file_id, io_stall_read_ms, io_stall_write_ms
FROM sys.dm_io_virtual_file_stats(null, null)
We can also check for the latch waits. SQL Server waits for PAGEIOLATCH_EX or PAGEIOLATCH_SH if the page is not in the buffer pool.
SELECT
wait_type,
waiting_tasks_count,
wait_time_ms,
signal_wait_time_ms,
(wait_time_ms - signal_wait_time_ms) 'io time waiting'
FROM sys.dm_os_wait_stats
WHERE wait_type IN ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX')
ORDER BY wait_type
The long waits of this type indicate a problem with the disk subsystem. The column wait_time_ms includes the time a worker spends in SUSPENDED state and in RUNNABLE state while the column signal_wait_time_ms represents the time a worker spends in RUNNABLE state. So the difference of the two (wait_time_ms – signal_wait_time_ms), actually represents the time spent waiting for I/O to complete.
Isolation and Troubleshooting of I/O Bottlenecks
To troubleshoot I/O bottlenecks you will need to look into - physical memory available to SQL Server and, - the queries with the highest I/O.
For troubleshooting memory, you can use the techniques already discussed.
Using DMVs to Troublehsoot I/O
We can use the following DMV to find the top 10 queries with the highest I/O per execution as follows :
SELECT TOP 10
(total_logical_reads/execution_count) AS avg_logical_reads,
(total_logical_writes/execution_count) AS avg_logical_writes,
(total_physical_reads/execution_count) AS avg_phys_reads,
execution_count,
(SELECT SUBSTRING(text, statement_start_offset/2 + 1,
(CASE WHEN statement_end_offset = -1
THEN LEN(CONVERT(nvarchar(MAX),text)) * 2
ELSE statement_end_offset
END - statement_start_offset)/2)
FROM sys.dm_exec_sql_text(sql_handle)) AS query_text,
plan_handle
FROM sys.dm_exec_query_stats
ORDER BY (total_logical_reads + total_logical_writes) DESC
Tempdb Bottlenecks
The SQL Server tempdb is a shared resource within the SQL Server instance, and all databases uses the same tempdb. The tempdb can be a bottleneck and with the new SQL Server it can be configured with its own set of memory, data and log files and CPU configurations.
Blocking
When a user submits a request/batch, the SQL Server assigns a worker and schedules it on the CPU to execute it. If the number of incoming requests far exceeds the capacity of CPU(s) to process it, the end user may perceive that the request is blocked or running slow. Poorly configured hardware configurations can cause blocking in SQL Server.
Detection of blocking
We can use the sys.dm_os_wait_stats DMV to detect blocking. The following query would list the top 10 waits encountered :
SELECT TOP 10
wait_type,
waiting_tasks_count AS tasks,
wait_time_ms,
max_wait_time_ms AS max_wait,
signal_wait_time_ms AS signal
FROM sys.dm_os_wait_stats
ORDER BY wait_time_ms DESC
We can use the DBCC command to clear the wait stats as follows :
DBCC SQLPERF("sys.dm_os_wait_stats",CLEAR);
Using Performance Monitor,we can also monitor the following counters :
- SQLServer:Locks: Average Wait Time (ms) - represents the average wait time (milliseconds) for each lock request that resulted in a wait.
- SQLServer:Locks: Lock Requests/Sec - represents the number of new locks and lock conversions requested from the lock manager
- SQLServer:Locks: Lock Wait Time (ms) - represents total wait time (milliseconds) for locks in the last second.
- SQLServer:Locks: Lock Waits/Sec - represents number of lock requests that could not be satisfied immediately and required the caller to wait before being granted the lock
- SQLServer:Locks: Number of Deadlocks/Sec - represents the number of lock requests that resulted in a deadlock
- SQLServer:General Statistics: Processes Blocked - represents the number of currently blocked processes
- SQLServer:Access Methods: Table Lock Escalations/Sec - represents the number of times locks were escalated to table-level granularity
Isolating and Troubleshooting Blocking Problems
Blocking is normal is an application but excessive blocking in undesirable. Here are some guidelines to reduce blocking :
- Shorten the duration of the transaction and run it at a lower isolation level
- Minimize the data that needs to be accessed by the transaction
- When doing DML operations on objects, try designing your application in such a way that you access objects in the same order
- If you are doing DML operations on a large number of rows, break it into smaller transactions to prevent lock escalation
We can use the sys.dm_tran_locks to find out all the locks that are being held and their status as follows :
SELECT resource_type, resource_associated_entity_id,
request_status, request_mode,request_session_id,
resource_description
FROM sys.dm_tran_locks
WHERE resource_database_id = db_id()
and we can find blocking information as follows :
SELECT
t1.resource_type,
t1.resource_database_id,
t1.resource_associated_entity_id,
t1.request_mode,
t1.request_session_id,
t2.blocking_session_id
FROM sys.dm_tran_locks as t1
INNER JOIN sys.dm_os_waiting_tasks as t2
ON t1.lock_owner_address = t2.resource_address;
The following query returns object information by using resource_associated_entity_id from the previous query. This query must be executed while you are connected to the database that contains the object.
SELECT object_name(object_id), *
FROM sys.partitions
WHERE hobt_id=<resource_associated_entity_id>
We can even get more information by combining other DMVs as follows :
SELECT
t1.resource_type,
'database' = DB_NAME(resource_database_id),
'blk object' = t1.resource_associated_entity_id,
t1.request_mode,
t1.request_session_id,
t2.blocking_session_id,
t2.wait_duration_ms,
(SELECT SUBSTRING(text, t3.statement_start_offset/2 + 1,
(CASE WHEN t3.statement_end_offset = -1
THEN LEN(CONVERT(nvarchar(max),text)) * 2
ELSE t3.statement_end_offset
END - t3.statement_start_offset)/2)
FROM sys.dm_exec_sql_text(sql_handle)) AS query_text,
t2.resource_description
FROM
sys.dm_tran_locks AS t1,
sys.dm_os_waiting_tasks AS t2,
sys.dm_exec_requests AS t3
WHERE
t1.lock_owner_address = t2.resource_address AND
t1.request_request_id = t3.request_id AND
t2.session_id = t3.session_id
We can find out more information on blocking on indexes using the sys.dm_db_index_operational_stats. The DMV function provides comprehensive index usage statistics including blocking experienced while accessing that index.
For example to find the lock counts on the indexes on the Person.Person table we can use the following query :
SELECT s.index_id,
i.name,
range_scan_count,
row_lock_count,
page_lock_count
FROM sys.dm_db_index_operational_stats(DB_ID(),
OBJECT_ID('Person.Person'), NULL, NULL) s
JOIN sys.indexes i
ON s.index_id = i.index_id and i.object_id = OBJECT_ID('Person.Person')
Performance vs. Price
When optimizing performance you should remember the Pareto Principle. In most cases, you will see 80% performance improvement by only fixing 20% of the problems with SQL Server. Here are general considerations :
- Use a baseline to measure performance against
- Count the cost of improving performance
Performance Baseline
Performance tuning should be a proactive process. A baseline should be created at the beginning of the process and used to measure against any deviations in performance.
Where to Focus Efforts
You should focus your effort on the SQL queries and stored procedures executed on the database more as compared to focusing your efforts on the hardware running SQL Server. You will gain a considerable amount of performance in the data access layer than you will from the hardware.
T-SQL Code and indexing were the top SQL Server root cause of poor performance from a survey conducted by Paul Radal.
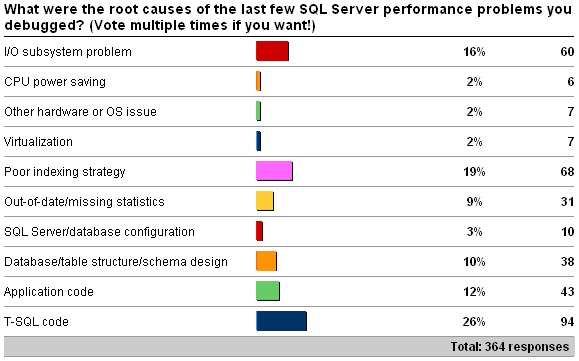
SQL Server Performance Killers
Here some issues that might degrade SQL Server Performance :
- Insufficient indexing
- Inaccurate statistics
- Improper query design
- Poorly generated execution plans
- Excessive blocking and deadlocks
- Non-set-based operations, usually T-SQL cursors
- Inappropriate database design
- Excessive fragmentation
- Nonreusable execution plans
- Frequent recompilation of queries
- Improper use of cursors
- Improper configuration of the database transaction log
- Excessive use or improper configuration of tempdb