Index Analysis
One of the best ways to reduce disk I/O is to use an index. An index allows SQL Server to find data in a table without scanning the entire table.
The following query scans the entire table to retrieve the data :
SELECT TOP 10
p.ProductID,
p.[Name],
p.StandardCost,
p.[Weight],
ROW_NUMBER() OVER (ORDER BY p.Name DESC) AS RowNumber
FROM Production.Product p
ORDER BY p.Name DESC;
The table will still be scanned if we were to add a WHERE clause on StandardCost column.
Index Terms
- Heap - A heap is a data structure where rows are stored without a specified order. In other words, it is a table without a clustered index.
- Clustered index - A table can only have one clustered index and the data is sorted on the clustered index.
- Nonclustered index - A B-Tree structure that contains the index key values and a pointer to the data row on the base table. It can be created on a heap on a clustered index. Each table can have up to 999 nonclustered indexes. A nonclustered index can optionally contain non-key columns when using the INCLUDE clause, which are particularly useful when covering a query.
- Unique index - a unique index does not allow two rows of data to have identical key values. A table can have one or more unique indexes.
- Primary key - A primary key is a key that uniquely identifies each record in the table and creates a unique index, which, by default, will also be a clustered index.
Creating a Primary Key
By default when a primary key is created, it creates a unique, clustered index. This is the behaviour when using the designer in SSMS and also the ALTER TABLE statement.
If you run the following queries, the will both produce a clustered index :
-- if you run the following code to create a primary key, where the CLUSTERED or NONCLUSTERED keywords are not specified
CREATE TABLE table1 (
col1 int NOT NULL,
col2 nchar(10) NULL,
CONSTRAINT PK_table1 PRIMARY KEY(col1)
)
-- or
CREATE TABLE table1
(
col1 int NOT NULL,
col2 nchar(10) NULL
)
GO
ALTER TABLE table1 ADD CONSTRAINT
PK_table1 PRIMARY KEY
(
col1
)

Create Index Syntax
The following is the syntax to creating an index :
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON <object> ( column [ ASC | DESC ] [ ,...n ] )
[ INCLUDE ( column_name [ ,...n ] ) ]
[ WHERE <filter_predicate> ]
[ WITH ( <relational_index_option> [ ,...n ] ) ]
[ ON { partition_scheme_name ( column_name )
Modifying the Index
The ALTER INDEX command is used to modify an existing table or view index (relational or XML) by disabling, rebuilding, or reorganizing the index; or by setting options on the index.
The syntax is as follows :
ALTER INDEX { index_name | ALL } ON <object>
{
REBUILD {
[ PARTITION = ALL ] [ WITH ( <rebuild_index_option> [ ,...n ] ) ]
| [ PARTITION = partition_number [ WITH ( <single_partition_rebuild_index_option> ) [ ,...n ] ]
}
| DISABLE
| REORGANIZE [ PARTITION = partition_number ] [ WITH ( <reorganize_option> ) ]
| SET ( <set_index_option> [ ,...n ] )
}
[ ; ]
Dropping an Index
We can the DROP INDEX command remove an existing index and the syntax is as follows :
DROP INDEX [ IF EXISTS ]
{ <drop_relational_or_xml_or_spatial_index> [ ,...n ]
| <drop_backward_compatible_index> [ ,...n ]
}
the following will drop the index name IX_ProductVendor_BusinessEntityID from the Purchasing.ProductVendor table.
DROP INDEX IX_ProductVendor_BusinessEntityID
ON Purchasing.ProductVendor;
GO
and we can also drop multiple indexes as follows :
DROP INDEX
IX_PurchaseOrderHeader_EmployeeID ON Purchasing.PurchaseOrderHeader,
IX_Address_StateProvinceID ON Person.Address;
GO
Dropping a PRIMARY KEY constraint online
Indexes that are created as the result of creating PRIMARY KEY or UNIQUE constraints cannot be dropped by using DROP INDEX. They are dropped using the ALTER TABLE DROP CONSTRAINT statement.
The following example deletes a clustered index with a PRIMARY KEY constraint by dropping the constraint. The ProductCostHistory table has no **FOREIGN KEY **constraints. If it did, those constraints would have to be removed first.
-- Set ONLINE = OFF to execute this example on editions other than Enterprise Edition.
ALTER TABLE Production.TransactionHistoryArchive
DROP CONSTRAINT PK_TransactionHistoryArchive_TransactionID
WITH (ONLINE = ON);
Creating Indexes
Let’s do a quick exercise to show some of these concepts and T-SQL statements mentioned in this section. Create a new table by running the following statement:
-- create a new table by running the following statement:
SELECT * INTO dbo.SalesOrderDetail
FROM Sales.SalesOrderDetail
View the indexes for the Table
-- let’s use the sys.indexes catalog view to inspect the table properties:
SELECT * FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.SalesOrderDetail')

Create a non-clustered index
-- let’s create a nonclustered index:
CREATE INDEX IX_ProductID ON dbo.SalesOrderDetail(ProductID)

Nonclustered indexes can have index_id values between 2 and 250 and between 256 and 1005. The values between 251 and 255 are reserved
Create a clustered index
-- now create a clustered index:
CREATE CLUSTERED INDEX IX_SalesOrderID_SalesOrderDetailID
ON dbo.SalesOrderDetail(SalesOrderID, SalesOrderDetailID)

Note that instead of a heap, now we have a clustered index and the index_id is now 1. A clustered index always has an index_id of 1. Internally, the nonclustered index has been rebuilt to now use a cluster key pointer rather than a row identifier (RID).
Dropping the nonclustered index will remove the index pages entirely, leaving only the clustered index:
-- dropping the nonclustered index will remove the index pages entirely, leaving only the clustered index:
DROP INDEX dbo.SalesOrderDetail.IX_ProductID
But notice that deleting the clustered index, which is considered the entire table, does not delete the underlying data, but simply changes the table structure to be a heap:
-- but notice that deleting the clustered index, which is considered the entire table
DROP INDEX dbo.SalesOrderDetail.IX_SalesOrderID_SalesOrderDetail
Choosing a Clustered Index
You definitely want to use a clustered index in the following cases:
- You frequently need to return data in a sorted order or query ranges of data. In this case, you would need to create the clustered index key on the column’s desired order.
- You frequently need to return data grouped together. In this case, you would need to create the clustered index key on the columns used by the GROUP BY clause.
Clustered vs. Nonclustered Indexes
The main considerations in choosing between a clustered and a nonclustered index are as follows:
- Number of rows to be retrieved
- Data-ordering requirement
- Index key width
- Column update frequency
- Lookup cost
- Any disk hot spots
Covering Indexes
A covering index is a nonclustered index built upon all the columns required to satisfy a SQL query without going to the heap or the clustered index. If a query encounters an index and does not need to refer to the underlying structures at all, then the index can be considered a covering index.
Using the following query you will notice that the column PostalCode is needed but we have to perform a lookup in order to retrieve the data not satisfied by the index :
-- for example, the following query is already covered by an existing index, IX_SalesOrderHeader_CustomerID
SELECT SalesOrderID, CustomerID FROM Sales.SalesOrderHeader
WHERE CustomerID = 16448
There is no need to access the base table at all. If we slightly change the query to also request the SalesPersonID column, this time, there is no index that covers the query :
-- if we slightly change the query to also request the SalesPersonID column
SELECT SalesOrderID, CustomerID, SalesPersonID FROM Sales.SalesOrderHeader
WHERE CustomerID = 16448
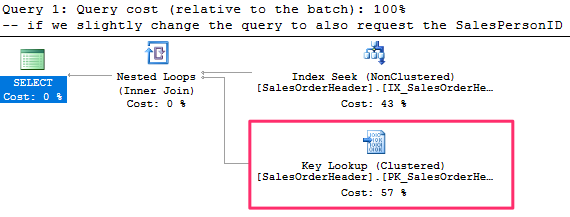
WE can use the INCLUDE keyword when creating the index in order to include the index column without adding it to the index keys as follows :
-- at this point, you may decide to just update an existing index to include the required column
CREATE INDEX IX_SalesOrderHeader_CustomerID_SalesPersonID
ON Sales.SalesOrderHeader(CustomerID)
INCLUDE (SalesPersonID
Re-run the query and notice the plan with an index seek. Drop the index :
-- finally, to clean up, drop the temporarily created index:
DROP INDEX Sales.SalesOrderHeader.IX_SalesOrderHeader_CustomerID_SalesPersonID
The INCLUDE is best used in the following cases:
- You don’t want to increase the size of the index keys, but you still want to make the index a covering index.
- You have a data type that cannot be an index key column but can be added to the nonclustered index through the INCLUDE command.
- You’ve already exceeded the maximum number of key columns for an index (although this is a problem best avoided).
Filtered Indexes
A filtered index is a nonclustered index that uses a filter, basically a WHERE clause, to create a highly selective set of keys against a column or columns that may not have good selectivity otherwise.
The Sales.SalesOrderHeader table has more than 30,000 rows. Of those rows, 27,000+ have a null value in the PurchaseOrderNumber column and the SalesPersonId column. If you wanted to get a simple list of purchase order numbers, the query might look like this:
SELECT soh.PurchaseOrderNumber,
soh.OrderDate,
soh.ShipDate,
soh.SalesPersonID
FROM Sales.SalesOrderHeader AS soh
WHERE PurchaseOrderNumber LIKE 'PO5%'
AND soh.SalesPersonID IS NOT NULL;
;
Running the query results in, as you might expect, a clustered index scan, and the following I/O and execution time.
To fix this, it is possible to create an index and include some of the columns from the query to make this a covering index.
CREATE NONCLUSTERED INDEX IX_Test
ON Sales.SalesOrderHeader(PurchaseOrderNumber,SalesPersonID)
INCLUDE (OrderDate,ShipDate);
Table 'SalesOrderHeader'. Scan count 1, logical reads 5
CPU time = 0 ms, elapsed time = 69 ms.
As you can see, the covering index dropped the reads from 689 to 5 and the time from 87 ms to 69 ms. Normally, this would be enough. Assume for a moment that this query has to be called frequently. Now, every bit of speed you can wring from it will pay dividends. Knowing that so much of the data in the indexed columns is null, you can adjust the index so that it filters out the null values, which aren’t used by the index anyway, reducing the size of the tree and therefore the amount of searching required.
CREATE NONCLUSTERED INDEX IX_Test
ON Sales.SalesOrderHeader(PurchaseOrderNumber,SalesPersonID)
INCLUDE (OrderDate,ShipDate)
WHERE PurchaseOrderNumber IS NOT NULL AND SalesPersonID IS NOT NULL
WITH (DROP_EXISTING = ON);
The final run of the query is visible in the following result :
Table 'SalesOrderHeader'. Scan count 1, logical reads 4
CPU time = 0 ms, elapsed time = 55 ms.
Filtered indexes improve performance in many ways.
- Improving the efficiency of queries by reducing the size of the index
- Reducing storage costs by making smaller indexes
- Cutting down on the costs of index maintenance because of the reduced size
Index Intersections
If a table has multiple indexes, then SQL Server can use multiple indexes to execute a query. SQL Server can take advantage of multiple indexes, selecting small subsets of data based on each index and then performing an intersection of the two subsets (that is, returning only those rows that meet all the criteria). SQL Server can exploit multiple indexes on a table and then employ a join algorithm to obtain the index intersection between the two subsets.
--SELECT * is intentionally used in this query
SELECT soh.*
FROM Sales.SalesOrderHeader AS soh
WHERE soh.SalesPersonID = 276
AND soh.OrderDate BETWEEN '4/1/2005' AND '7/1/2005';
There’s no index on the OrderDate column so SQL Server will perform a scan of the table. We can include the column or create a new non-clustered index on the table as follows :
CREATE NONCLUSTERED INDEX IX_Test
ON Sales.SalesOrderHeader (OrderDate);
And when we run the query you will notice SQL Server have used both indexes and created an index intersection.
Index Joins
The index join is a variation of index intersection, where the covering index technique is applied to the index intersection. If no single index covers a query but multiple indexes together can cover the query, SQL Server can use an index join to satisfy the query fully without going to the base table.
Let’s look at this indexing technique at work. Make a slight modification to the query from the “Index Intersections” section like this:
SELECT soh.SalesPersonID,
soh.OrderDate
FROM Sales.SalesOrderHeader AS soh
WHERE soh.SalesPersonID = 276
AND soh.OrderDate BETWEEN '4/1/2005' AND '7/1/2005';
Since the query requires the value of the OrderDate column also, the optimizer selected the clustered index to retrieve values for all the columns referred to in the query. If an index is created on the OrderDate column like this:
CREATE NONCLUSTERED INDEX IX_Test
ON Sales.SalesOrderHeader (OrderDate ASC);
and the query is rerun.
The combination of the two indexes acts like a covering index reducing the reads against the table from 689 to 4 because it’s using two Index Seek operations joined together instead of a clustered index scan.
Since SQL Server didnt use the index, we can use a hint as follows :
SELECT soh.SalesPersonID,
soh.OrderDate
FROM Sales.SalesOrderHeader AS soh WITH
(INDEX (IX_Test,
IX_SalesOrderHeader_SalesPersonID))
WHERE soh.OrderDate BETWEEN '4/1/2002' AND '7/1/2002';
The reads have clearly increased, and you have work tables and work files that use tempdb to store data during the processing. Most of the time, the optimizer makes good choices when it comes to indexes and execution plans.
Index Operations
Equality and inequality operators can be used in a predicate, including =, <, >, <=, >=, <>, !=, !<, !>, BETWEEN, and IN for seek operations.
The following predicates can be matched to an Index Seek operation if there is an index on the specified column, or a multicolumn index with that column as a leading index key:
- ProductID = 771
- UnitPrice < 3.975
- LastName = ’Allen’
- LastName LIKE ’Brown%’
The following query produces an Index Seek :
SELECT ProductID, SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE ProductID = 771
The SalesOrderDetail table has a multicolumn index with ProductID as the leading column.
An index cannot be used to seek on some complex expressions, expressions using functions, or strings with a leading wildcard character, as in the following predicates:
- ABS(ProductID) = 771
- UnitPrice + 1 < 3.975
- LastName LIKE ’%Allen’
- UPPER(LastName) = ’Allen’
The following query produces a scan because of the function in the WHERE cause :
-- compare the following query to the previous example
SELECT ProductID, SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE ABS(ProductID) = 771
In the case of a multicolumn index, SQL Server can only use the index to seek on the second column if there is an equality predicate on the first column. So SQL Server can use a multicolumn index to seek on both columns in the following cases, supposing that a multicolumn index exists on both columns in the order presented:
- ProductID = 771 AND SalesOrderID > 34000
- LastName = ’Smith’ AND FirstName = ’Ian’
That being said, if there is no equality predicate on the first column, or if the predicate cannot be evaluated on the second column, as is the case in a complex expression, then SQL Server may still only be able to use a multicolumn index to seek on just the first column, as in the following examples:
- ProductID < 771 AND SalesOrderID = 34000
- LastName > ’Smith’ AND FirstName = ’Ian’
- ProductID = 771 AND ABS(SalesOrderID) = 34000
However, SQL Server is not able to use a multicolumn index for an Index Seek in the following examples because it is not even able to search on the first column:
- ABS(ProductID) = 771 AND SalesOrderID = 34000
- LastName LIKE ’%Smith’ AND FirstName = ’Ian’
The following will only seek on the ProductID column :
SELECT ProductID, SalesOrderID, SalesOrderDetailID
FROM Sales.SalesOrderDetail
WHERE ProductID = 771 AND ABS(SalesOrderID) = 45233
Missing Indexes
SQL Server does provide a second approach that can help you find useful indexes for your existing queries. Let’s take a quick look to see how this feature works. Create the dbo.SalesOrderDetail table on the AdventureWorks2012 database by running the following statement:
-- create the dbo.SalesOrderDetail table on the AdventureWorks2012 database by running the following statement:
SELECT * INTO dbo.SalesOrderDetail
FROM Sales.SalesOrderDetail
Run this query and request a graphical or XML execution plan:
-- run this query and request a graphical or XML execution plan:
SELECT * FROM dbo.SalesOrderDetail
WHERE SalesOrderID = 43670 AND SalesOrderDetailID > 112
This query could benefit from an index on the SalesOrderID and SalesOrderDetailID columns, but no missing indexes information is shown this time. One limitation of the Missing Indexes feature that this example has revealed is that it does not work with a trivial plan optimization.
In our case, we’re just going to create a nonrelated index by running the following statement:
CREATE INDEX IX_ProductID ON dbo.SalesOrderDetail(ProductID)
What is significant about this is that, although the index created will not be used by our previous query, the query no longer qualifies for a trivial plan. Run the query again and observe the generated by now includes information about missing indexes.
-- create the recommended index, after you provide a name for it, by running the following statement:
CREATE NONCLUSTERED INDEX IX_SalesOrderID_SalesOrderDetailID
ON [dbo].[SalesOrderDetail]([SalesOrderID], [SalesOrderDetailID]
If you run our previous SELECT statement again and look at the execution plan, this time you’ll see an Index Seek operator using the index you’ve just created, and both the Missing Index warning and the MissingIndex element of the XML plan are gone.
Finally, remove the dbo.SalesOrderDetail table you’ve just created by running the following statement:
DROP TABLE dbo.SalesOrderDetail
Index Fragmentation
Fragmentation happens when the logical order of pages in an index does not match the physical order in the data file. Because fragmentation can affect the performance of some queries, you need to monitor the fragmentation level of your indexes and, if required, perform reorganize or rebuild operations on them.
- It is also worth clarifying that fragmentation may affect only queries performing scans or range scans; queries performing index seeks may not be affected at all.
- The query optimizer does not consider fragmentation either, so the plans it produces will be the same whether you have high fragmentation or no fragmentation at all.
- You can use the sys.dm_db_index_physical_stats DMF to analyze the fragmentation level of your indexes
The following example will return fragmentation information for the Sales.SalesOrderDetail of the AdventureWorks2012 database:
-- the following example will return fragmentation information for the Sales.SalesOrderDetail table
SELECT a.index_id, name, avg_fragmentation_in_percent, fragment_count,
avg_fragment_size_in_pages
FROM sys.dm_db_index_physical_stats (DB_ID('AdventureWorks2012'),
OBJECT_ID('Sales.SalesOrderDetail'), NULL, NULL, NULL) AS a
JOIN sys.indexes AS b ON a.object_id = b.object_id AND a.index_id = b.index_id
To rebuild all the indexes on the SalesOrderDetail table, use the following statement:
ALTER INDEX ALL ON Sales.SalesOrderDetail REBUILD
In case you need to reorganize the index, which is not the case here, you can use a command like this:
ALTER INDEX ALL ON Sales.SalesOrderDetail REORGANIZE
Rebuilding Indexes
Rebuilding an index drops and re-creates the index. This removes fragmentation, reclaims disk space by compacting the pages based on the specified or existing fill factor setting, and reorders the index rows in contiguous pages. When ALL is specified, all indexes on the table are dropped and rebuilt in a single transaction. FOREIGN KEY constraints do not have to be dropped in advance. When indexes with 128 extents or more are rebuilt, the Database Engine defers the actual page deallocations, and their associated locks, until after the transaction commits.
Rebuilding or reorganizing small indexes often does not reduce fragmentation. The pages of small indexes are sometimes stored on mixed extents. Mixed extents are shared by up to eight objects, so the fragmentation in a small index might not be reduced after reorganizing or rebuilding it.
Rebuilding an index
The following example rebuilds a single index on the Employee table in the AdventureWorks2012 database.
ALTER INDEX PK_Employee_EmployeeID ON HumanResources.Employee REBUILD;
Rebuilding all indexes on a table and specifying options
The following example specifies the keyword ALL. This rebuilds all indexes associated with the table Production.Product in the AdventureWorks2012 database. Three options are specified.
ALTER INDEX ALL ON Production.Product
REBUILD WITH (FILLFACTOR = 80, SORT_IN_TEMPDB = ON, STATISTICS_NORECOMPUTE = ON);
Setting options on an index
The following example sets several options on the index AK_SalesOrderHeader_SalesOrderNumber in the AdventureWorks2012 database.
ALTER INDEX AK_SalesOrderHeader_SalesOrderNumber ON
Sales.SalesOrderHeader
SET (
STATISTICS_NORECOMPUTE = ON,
IGNORE_DUP_KEY = ON,
ALLOW_PAGE_LOCKS = ON
) ;
GO
Disabling an index
The following example disables a nonclustered index on the Employee table in the AdventureWorks2012 database.
ALTER INDEX IX_Employee_ManagerID ON HumanResources.Employee DISABLE;
Reorganizing Indexes
Reorganizing an index uses minimal system resources. It defragments the leaf level of clustered and nonclustered indexes on tables and views by physically reordering the leaf-level pages to match the logical, left to right, order of the leaf nodes. Reorganizing also compacts the index pages. Compaction is based on the existing fill factor value.
Unused Indexes
The sys.dm_db_index_usage_stats DMV can be used to learn about the operations performed by your indexes. It is especially helpful in discovering indexes that are not used by any query, or are only minimally used.
As an example, run the following code to create a new table with a nonclustered index:
- as an example, run the following code to create a new table with a nonclustered index:
SELECT * INTO dbo.SalesOrderDetail
FROM Sales.SalesOrderDetail
CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.SalesOrderDetail(ProductID)
When you run the following query, it will initially contain only one record, which was created because of table access performed when the IX_ProductID index was created:
- when you run the following query, it will initially contain only one record
SELECT DB_NAME(database_id) AS database_name,
OBJECT_NAME(s.object_id) AS object_name, i.name, s.*
FROM sys.dm_db_index_usage_stats s JOIN sys.indexes i
ON s.object_id = i.object_id AND s.index_id = i.index_id
AND OBJECT_ID('dbo.SalesOrderDetail') = s.object_id
However, the values that we will be inspecting in this exercise—user_seeks, user_scans, user_lookups, and user_updates—are all set to 0. Now run the following query, let’s say, three times:
SELECT * FROM dbo.SalesOrderDetail
This query is using a Table Scan operator, so, if you rerun our previous query using the sys.dm_db_index_usage_stats DMV, it will show the value 3 on the user_scans column.
Run the next query, which uses an Index Seek, twice. After the query is executed, a new record will be added for the nonclustered index, and the user_seeks counter will show a value of 2.
-- run the next query, which uses an Index Seek, twice
SELECT ProductID FROM dbo.SalesOrderDetail
WHERE ProductID = 773
Now, run the following query four times, and it will use both Index Seek and RID Lookup operators. Because the user_seeks for the nonclustered index had a value of 2, it will be updated to 6, and the user_lookups value for the heap will be updated to 4.
-- now, run the following query four times
SELECT * FROM dbo.SalesOrderDetail
WHERE ProductID = 773
Finally, run the following query once:
-- finally, run the following query once:
UPDATE dbo.SalesOrderDetail
SET ProductID = 666
WHERE ProductID = 927
Note that the UPDATE statement is doing an Index Seek and a Table Update, so user_seek will be updated for the index, and user_updates will be updated once for both the nonclustered index and the heap.
Finally, drop the table you just created:
DROP TABLE dbo.SalesOrderDetail
Non-clustered Indexes Clustered vs. Non-clustered Indexes Advanced Indexing Techniques
A nonclustered index does not affect the order of the data in the table pages because the leaf pages of a nonclustered index and the data pages of the table are separate.
If all the columns required by the query are available in the index itself, then access to the data page is not required. This is known as a covering index.
When Not to Use a Nonclustered Index
Nonclustered indexes are not suitable for queries that retrieve a large number of rows. Such queries are better served with a clustered index, which doesn’t require a separate lookup to retrieve a data row.
When to Use a Nonclustered Index
A nonclustered index is most useful when all you want to do is retrieve a small number of rows and columns from a large table. As the number of columns to be retrieved increases, the ability to have a covering index decreases.
Relationship with Nonclustered Indexes
An index row of a nonclustered index contains a pointer to the corresponding data row of the table. This pointer is called a row locator. The value of the row locator depends on whether the data pages are stored in a heap or on a clustered index. For a nonclustered index, the row locator is a pointer to the row identifier (RID) for the data row in a heap. For a table with a clustered index, the row locator is the clustered index key value.
Indexed Views
A database view can be materialized on the disk by creating a unique clustered index on the view. Such a view is referred to as an indexed view or a materialized view. After a unique clustered index is created on the view, the view’s result set is materialized immediately and persisted in physical storage in the database, saving the overhead of performing costly operations during query execution. After the view is materialized, multiple nonclustered indexes can be created on the indexed view. Effectively, this turns a view (again, just a query) into a real table with defined storage.
Benefit
You can use an indexed view to increase the performance of a query in the following ways:
- Aggregations can be precomputed and stored in the indexed view to minimize expensive computations during query execution.
- Tables can be prejoined, and the resulting data set can be materialized.
- Combinations of joins or aggregations can be materialized
Overhead
Indexed views can produce major overhead on an OLTP database. Some of the overheads of indexed views are as follows:
Any change in the base tables has to be reflected in the indexed view by executing the view’s SELECT statement. Any changes to a base table on which an indexed view is defined may initiate one or more changes in the nonclustered indexes of the indexed view. The clustered index will also have to be changed if the clustering key is updated. The indexed view adds to the ongoing maintenance overhead of the database. Additional storage is required in the database.
Usage Scenarios
Reporting systems benefit the most from indexed views. OLTP systems with frequent writes may not be able to take advantage of the indexed views because of the increased maintenance cost associated with updating both the view and the underlying base tables. The net performance improvement provided by an indexed view is the difference between the total query execution savings offered by the view and the cost of storing and maintaining the view.
Index Compression
Compressing an index means getting more key information onto a single page. This can lead to significant performance improvements because fewer pages and fewer index levels are needed to store the index. There will be overhead in the CPU as the key values in the index are compressed and decompressed, so this may not be a solution for all indexes. Memory benefits also because the compressed pages are stored in memory in a compressed state.
By default, an index will be not be compressed. You have to explicitly call for the index to be compressed when you create the index. There are two types of compression: row- and page-level compression.
e.g we can compress an index as follows :
CREATE NONCLUSTERED INDEX IX_Comp_Test
ON Person.Address (City,PostalCode)
WITH (DATA_COMPRESSION = ROW);
and with page compression as follows :
CREATE NONCLUSTERED INDEX IX_Comp_Page_Test
ON Person.Address (City,PostalCode)
WITH (DATA_COMPRESSION = PAGE);
We can check the compressed pages in an index as follows :
SELECT i.Name,
i.type_desc,
s.page_count,
s.record_count,
s.index_level,
compressed_page_count
FROM sys.indexes i
JOIN sys.dm_db_index_physical_stats(DB_ID(N'AdventureWorks2012'),
OBJECT_ID(N'Person.Address'),NULL,
NULL,'DETAILED') AS s
ON i.index_id = s.index_id
WHERE i.OBJECT_ID = OBJECT_ID(N'Person.Address');
Columnstore Indexes
Introduced in SQL Server 2012, the columnstore index is used to index information by columns rather than by rows. This is especially useful when working within data warehousing systems where large amounts of data have to be aggregated and accessed quickly.
Index Overhead
The performance benefit of indexes does come at a cost. Tables with indexes require more storage and memory space for the index pages in addition to the data pages of the table. Data manipulation queries (INSERT, UPDATE, and DELETE statements, or the CUD part of Create, Read, Update, Delete [CRUD]) can take longer, and more processing time is required to maintain the indexes of constantly changing tables. When you have to deal with the existing system, you should ensure that the performance benefits of an index outweigh the extra cost in processing resources
Index Design Recommendations
The main recommendations for index design are as follows:
- Examine the WHERE clause and JOIN criteria columns.
- Use narrow indexes.
- Examine column uniqueness.
- Examine the column data type.
- Consider column order.
- Consider the type of index (clustered versus nonclustered)s