Boomark Lookup Analysis
Purpose of Bookmark Lookups
A major overhead associated with nonclustered indexes is the cost of excessive lookups, formerly known as bookmark lookups, which are a mechanism to navigate from a nonclustered index row to the corresponding data row in the clustered index or the heap.
When a SQL query requests information through a query, the optimizer can use a nonclustered index, if available, on the columns in the WHERE or JOIN clause to retrieve the data. If the query refers to columns that are not part of the nonclustered index being used to retrieve the data, then navigation is required from the index row to the corresponding data row in the table to access these remaining columns.
For example, in the following SELECT statement, if the nonclustered index used by the optimizer doesn’t include all the columns, navigation will be required from a nonclustered index row to the data row in the clustered index or heap to retrieve the value of those columns:
SELECT p.[Name],
AVG(sod.LineTotal)
FROM Sales.SalesOrderDetail AS sod
JOIN Production.Product p
ON sod.ProductID = p.ProductID
WHERE sod.ProductID = 776
GROUP BY sod.CarrierTrackingNumber,
p.[Name]
HAVING MAX(sod.OrderQty) > 1
ORDER BY MIN(sod.LineTotal);
SELECT *
FROM Sales.SalesOrderDetail AS sod
WHERE sod.ProductID = 776 ;
Drawbacks of Bookmark Lookups
A lookup requires data page access in addition to index page access. Accessing two sets of pages increases the number of logical reads for the query. Additionally, if the pages are not available in memory, a lookup will probably require a random (or nonsequential) I/O operation on the disk to jump from the index page to the data page as well as requiring the necessary CPU power to marshal this data and perform the necessary operations. This is because, for a large table, the index page and the corresponding data page usually won’t be directly next to each other on the disk.
Analyzing the Cause of a Bookmark Lookup
Since a lookup can be a costly operation, you should analyze what causes a query plan to choose a lookup step in an execution plan. You may find that you are able to avoid the lookup by including the missing columns in the nonclustered index key or as INCLUDE columns at the index page level and thereby avoid the cost overhead associated with the lookup.
To learn how to identify the columns not included in the nonclustered index, consider the following query, which pulls information from the HumanResources.Employee table based on NationalIDNumber:
SELECT NationalIDNumber,
JobTitle,
HireDate
FROM HumanResources.Employee AS e
WHERE e.NationalIDNumber = '693168613' ;
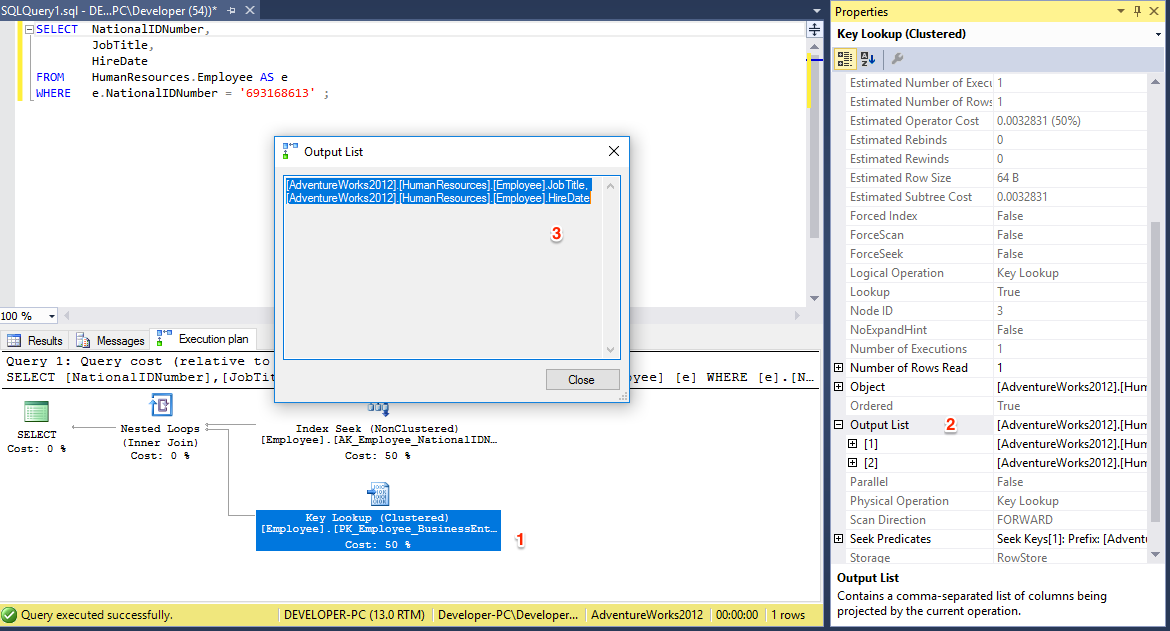
The SELECT statement refers to columns NationalIDNumber, JobTitle, and HireDate. The nonclustered index on column NationalIDNumber doesn’t provide values for columns JobTitle and HireDate, so a lookup operation was required to retrieve those columns from the data storage location.
If you look at the properties on the Key Lookup (Clustered) operation, you can see the output list for the operation. This shows you the columns being output by the lookup. To get the list of output columns quickly and easily and be able to copy them, right-click the operator, which in this case is Key Lookup (Clustered).
Resolving Bookmark Lookups
Since the relative cost of a lookup can be high, you should, wherever possible, try to get rid of lookup operations.
Using a Clustered Index
For a clustered index, the leaf page of the index is the same as the data page of the table. Therefore, when reading the values of the clustered index key columns, the database engine can also read the values of other columns without any navigation from the index row.
Using a Covering Index
To understand how you can use a covering index to avoid a lookup, examine the query against the HumanResources.Employee table again.
SELECT NationalIDNumber,
JobTitle,
HireDate
FROM HumanResources.Employee AS e
WHERE e.NationalIDNumber = '693168613';
To avoid this bookmark, you can add the columns referred to in the query, JobTitle and HireDate, directly to the nonclustered index key. This will make the nonclustered index a covering index for this query because all columns can be retrieved from the index without having to go to the heap or clustered index.
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON
[HumanResources].[Employee]
(NationalIDNumber ASC,
JobTitle ASC,
HireDate ASC )
WITH DROP_EXISTING;
There are a couple of caveats to creating a covering index by changing the key, however. If you add too many columns to a nonclustered index, it becomes wider. The index maintenance cost associated with the action queries can increase.
Another way to arrive at the covering index, without reshaping the index by adding key columns, is to use the INCLUDE columns. Change the index to look like this:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber]
ON [HumanResources].[Employee]
(NationalIDNumber ASC)
INCLUDE (JobTitle,HireDate)
WITH DROP_EXISTING ;
Because the data is stored at the leaf level of the index, when the index is used to retrieve the key values, the rest of the columns in the INCLUDE statement are available for use, almost like they were part of the key